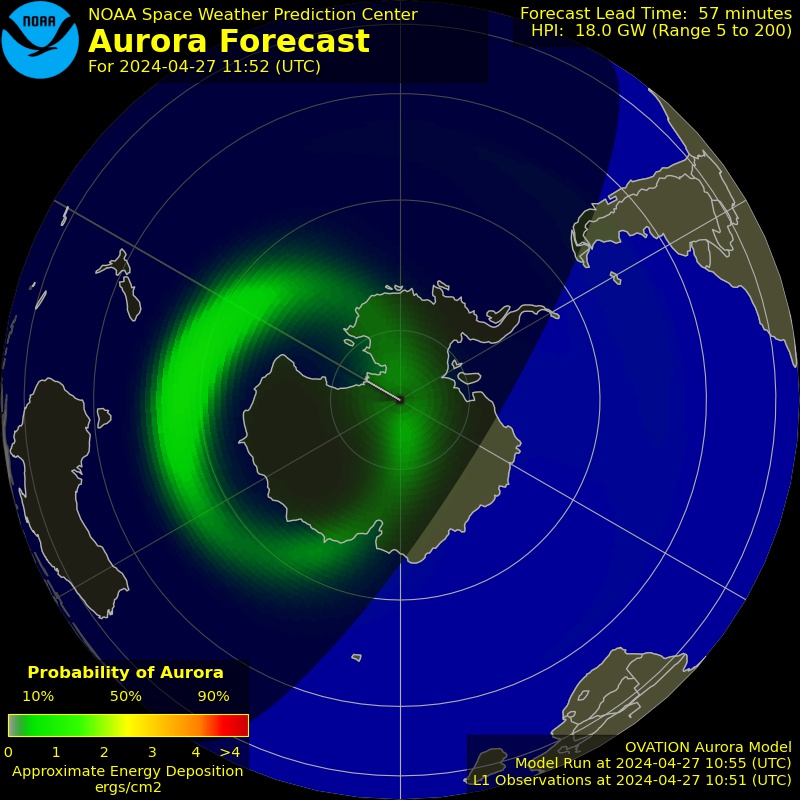
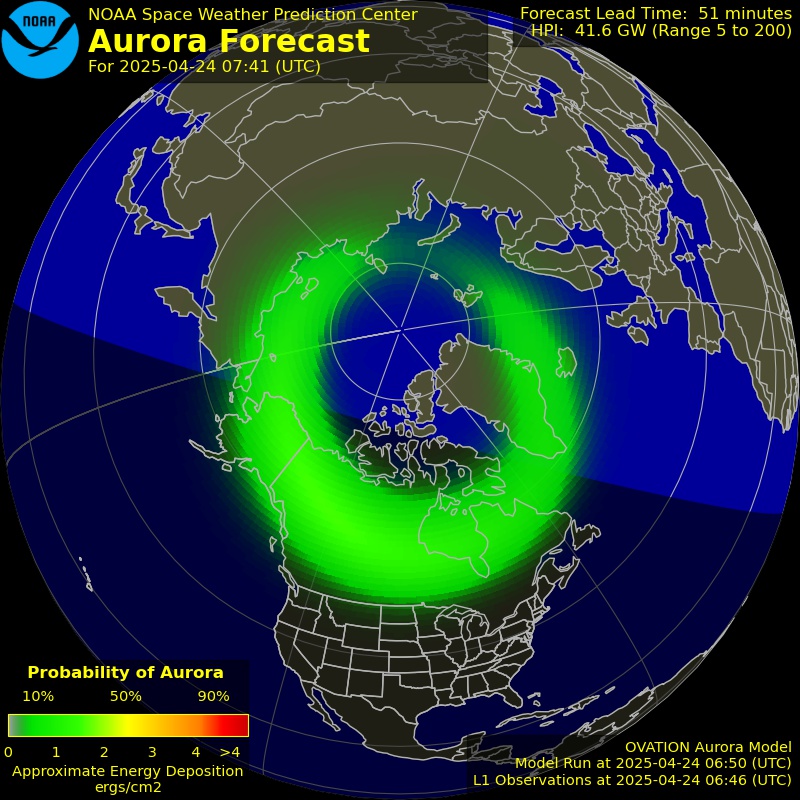
Il secondo appuntamento con il corso di astronomia organizzato dal GAV è dedicato alla meccanica celeste: la disciplina che si occupa di studiare le orbite dei corpi celesti naturali ed artificiali.
La conferenza presenta una panoramica introduttiva ai principali risultati raggiunti negli ultimi due secoli riguardo le orbite, le risonanze, l’obliquità … ottenuti grazie allo sforzo di molti astronomi: da Galileo, a Laskar passando per Newton, Keplero, Laplace, Lagrange ed altri ancora. A bordo di una sonda interplanetaria visiteremo i Giganti Gassosi ed i Giganti Ghiacciati soffermandoci sulle particolarità che li caratterizzano.
Verrà affrontato il problema della stabilità del Sistema Solare nel suo complesso alla luce dei risultati delle ultime simulazioni, unitamente ad una breve digressione storica della materia.
La conferenza avrà luogo venerdì 8 Marzo presso Villa Camperio, via Confalonieri 55 - Villasanta (MB)
Concludiamo gli articoli sui NEA con un’ultima analisi: l’obiettivo è quello di presentare un modello statistico in grado di classificare i NEA in una delle quattro classi: Aten, Amor, Apollo ed Atira. Per una breve descrizione del funzionamento degli algoritmi presenti si veda anche l’articolo precedente qui.
dati di input: componenti (semiasse maggiore, perielio, afelio) del dataset
dati di output: componente (classe di appartenenza) del dataset.
La classe è stata codificata in un numero secondo il seguente schema:
Classe NEA
Codifica numerica per l’algoritmo di ML
Amor
0
Apollo
1
Aten
2
Atira
3
Vengono presentati i risultati di tre modelli:
Decision Tree
K-Neighbors
Random Forest
Decision Tree: la descrizione del modello è la stesso descritto in precedenza usato per la classificazione in base alla pericolosità.
Diagramma generato dall’autore in linguaggio Python con le librerie scikit-learn
Risultati Decision Tree: la matrice di confusione ha una dimensione 4 x 4 prodotto cartesiano delle quattro classi. Il contenuto della diagonale principale indica il numero di NEA che il modello ha correttamente identificato con la stessa classe fornita dal dataset iniziale. Il contenuto della matrice nella posizione (i, j) con i ≠j rappresenta il numero di NEA appartenente alla classe i ma che il modello identifica erroneamente di classe j. Il modello identifica correttamente tutti i NEA di classe Atira (codice = 3 nella matrice), mentre sbaglia completamente a classificare I NEA di classe Aten (codice = 2 nella matrice) Non è possibile disegnare il diagramma di colore in quanto il modello ha tre variabili di ingresso e quattro possibili valori di uscita e non è rappresentabile su un piano o nello spazio.
K-Neighbors: la descrizione del modello è la stesso descritto in precedenza usato per la classificazione in base alla pericolosità. Come in precedenza viene dapprima stimato il valore di K ottimale usato nel modello predittivo: sono stati valutati dieci classificatori K-Neighbors () e selezionato il valore di K per il quale l’accuratezza è massima. Il modello ottimale si ottiene per K = 9.
Relazione fra efficienza dell’algoritmo K-Neighbors al variare del parametro K. Il valore ottimo di accuratezza si ottiene per K=9 (grafico dell’autore)
Risultati K-Neighbors: questo modello presenta un’accuratezza migliore fra quelli analizzati per questa classificazione: i risultati sono superiori sia rispetto al modello precedente che al successivo.
Random Forest: questo classificatore implementa un algoritmo che combina l’output di più strutture ad albero decisionali per raggiungere un unico risultato. Si costruisce una serie di strutture ad albero decisionali e ogni struttura ad albero è un insieme composto da un campione di dati tratto da un set di addestramento con sostituzione. La classificazione avviene a maggioranza: la variabile categoriale più frequente. Stessi campioni del dataset possono appartenere a diversi sottoinsiemi di analisi.
Gli algoritmi di Random Forest hanno tre iperparametri principali, che devono essere impostati prima dell’addestramento.
Diagramma generato dall’autore in linguaggio Python con le librerie scikit-learn
Risultati Random Forest: l’algoritmo offre un’accuratezza intermedia fra quelli analizzati: anch’esso riesce a classificare i NEA di tipo Atira e Amor ma classifica erroneamente tutti i NEA di tipo Apollo.
Il modello K-Neighbors presenta la migliore accuratezza, riuscendo a classificare correttamente una buona percentuale di NEA di tipo Aten.
Per ottenere risultati ancora migliori si può pensare di introdurre modelli più complessi utilizzando algoritmi di Deep Learning e reti neurali (la cui descrizione ed utilizzo esula dagli scopi di questo articolo)
Si conclude l’analisi mostrando I passaggi dei NEA pericolosi negli anni passata e futuri: ove presente viene indicato anche il diametro medio dell’oggetto celeste e la distanza minima di passaggio espresso in distanza media Terra-Luna (384.400 Km).
Molti oggetti nel passato recente sono transitati a distanza molto ravvicinata da noi: nel 2020 l’asteroide VT42020 VT4 è transitato a solo 0,01754 volte la distanza Terra-Luna. Nel 2029 è previsto l’incontro con 99942 Apophis, un NEA pericoloso di cui molto si è discusso: allo stato attuale però la sua pericolosità è stata declassata.
Diagramma generato dall’autore in linguaggio Python con le librerie scikit-learn
Diagramma di avvicinamento di Apophis nel 2029 generato dall’autore
L’incontro avverrà nell’Aprile 2029 e data l’elevata numerosità dei NEA (si suppone ce ne siano ancora migliaia da catalogare) l’incontro o il passaggio ravvicinato della Terra con un NEA è un evento normale.
Mediamente ogni anno ci sono circa 1600 passaggi ravvicinati di NEA alla Terra: nella prima settimana di Gennaio 2024 la Terra ha incontrato 24 NEA.
Diagramma generato dall’autore in linguaggio Python con le librerie scikit-learn
Dal database del CNEOS si evidenzia che quest’anno la Terra incontrerà ben 24 NEA catalogati come pericolosi: il più grande di essi è NK42013 di classe Apollo con un diametro minimo stimato di 460 metri che passerà ad una distanza di 8.5 volte la distanza media Terra-Luna (circa 3.300.000 Km).
Diagramma generato dall’autore in linguaggio Python con le librerie scikit-learn
NK42013 è un asteroide comunque con le dimensioni molto piccole in confronto a quello che 65 milioni di anni fa fu la concausa che portò all’estinzione dei dinosauri.
Domanda: supponete che un asteroide on un diametro compreso fra 10 e 20 Km è destinato ad entrare in atmosfera e ad impattare sulla Terra. Avete a disposizione solo una settimana prima dell’incontro. Cosa fareste nel tempo rimasto?
Dopo aver introdotto l’argomento nel precedente articolo, procediamo alla costruzione di due sistemi di classificazione con supervisione dei NEA.
L’obiettivo è di classificare i NEA per:
pericolosità (PHA, non PHA)
tipo (ATE, APO, AMO ed IEO)
Gli algoritmi con supervisione sono una classe di algoritmi di classificazione che si basano su un modello di addestramento etichettati per fare una previsione su nuovi dati.
A partire dal dataset iniziale, per entrambe le classificazioni vengono eseguiti i seguenti passi:
si filtra il dataset mantenendo le componenti X sono necessari alla classificazione:
moid, H per la classificazione di pericolosità
a, q, Q per la classificazione di tipo
si identifica la componente Y di stima (oggetto della stima):
per la classificazione di pericolosità (PHA)
classe per la classificazione di tipo
si sostituisce l’etichetta della componente di stima con una enumerazione, per ognuna delle due analisi.
si normalizzano i dati in un’unica scala commensurabile uguale ad ogni caratteristica: una distribuzione
si suddivide il dataset in due parti:
del dataset X usato come training per l’algoritmo
del dataset X usato come test e validazione dell’algoritmo.
del dataset Y usato come training per l’algoritmo.
del dataset Y usato come test e validazione dell’algoritmo: costituisce la baseline di riferimento.
si costruisce il modello matematico
Si applica il modello M per stimare
Si valuta la bontà del modello confrontanto con costruendo la matrice di confusione
Si calcolano i principali indici statistici (metriche) di validazione: precisione, accuratezza ed F1.
Modello usato per gli algoritmi di Machine Learning con la suddivisione del dataset in sottoinsieme di training e testing (disegno dell’autore)
Le tre principali metriche sono rappresentate da:
accuratezza: che risponde alla domanda quanto le predizioni sono vere?
precisione: che risponde alla domanda fra tutte quelle positive/negative, quante sono vere?
richiamo: ovverora tutte quelle che dovrebbero essere previste come vere, quante lo sono veramente? (errore del primo tipo)
indice F1: misura statistica che combina richiamo e precision.
L’obiettivo è presentare un modello statistico in grado di classificare i NEA in due classi: NEA pericolosi (PHA) o NEA non pericolosi (non PHA). Vengono presentati i risultati di tre modelli:
Support Vector Machine (SVM)
K-Neighbors
Decision tree
Per maggiori dettagli riguardo il principio di funzionamento di ogni modello si rimanda ai link visualizzati nei diagrammi presenti nelle figure sottostanti.
SVM: questo classificatore separa i punti usando un iperpiano con il massimo margine di separazione. L’algoritmo lavora in maniera iterativa individuando l’iperpiano ottimale (massimo) che separa il dataset in due zone entro i quali i nuovi dati verranno classificati minimizzando l’errore.
Diagrammi generati dall’autore in linguaggio Python con le librerie scikit-learn
Risultati SVM: Il modello possiede un’accuratezza del 96,9232%. Classifica molto bene i NEA della classe PHA, tuttavia presenta poca precisione. La matrice di confusione mostra che il modello presenta molti errori, in particolare sulla diagonale secondaria si evidenzia la presenza di molti falsi positive e falsi negativi. Ci sono 239 NEA che il modello identifica come non pericolosi quando in realtà nel dataset principale lo sono: si tratta di un errore grave, in quanto il modello sottovaluta il problema. Meno rilevante, ma non secondario, è il secondo tipo di errore: il modello identifica come pericolosi 124 NEA che in realtà non lo sono. In entrambi i casi è necessaria un’analisi approfondita con un modello più efficace oppure uno studio approfondito da parte degli astronomi.1 Sulla diagonale principale della matrice di confusione abbiamo il numero dei NEA correttamente identificati come PHA (598) oppure non PHA (10837).
Viene riportato anche il diagramma di colore, dove sulla ascissa viene espresso il moid, sull’ordinate H (magnitudine assoluta). Ogni punto colorato sul grafico rappresenta il valore della componente pericolosità: verde scuro per non PHA, verde chiaro per PHA. Viene disegnato anche l’iperpiano che separa le due classi con i margini massimi: essendo l’iperpiano per definizione una retta, esso non è in grado di dividere in maniera netta ed esclusiva la componente di previsione PHA, introducendo gli errori di valutazione evidenziati precedentemente.
K-Neighbors: questo classificatore usa il concetto di prossimità per fare previsioni sul raggruppamento a cui appartiene il dato in esame basandosi sull’ipotesi che punti ‘simili’ possono trovarsi vicini tra loro. L’assegnazione avviene per maggioranza (o per superamento di una soglia percentuale) analizzando i K punti più vicini ad ogni element del dataset. Serve quindi introdurre il concetto di distanza e definire una metrica per l’assegnamento della classe. Ci sono diverse metriche che si basano sulle seguenti definizioni di distanza:
Distanza di Hamming
Distanza di Manhattan
Distanza Euclidea (usata in questa analisi)
K rappresenta il parametron di prossiimità in base al quale cambia il numero dei vicini e quindi, l’associazione con la classe di appartenenza e la bontà del classificatore. Nel presente lavoro sono stati valutati dieci classificatori KNeighbors () e selezionato il valore di K per il quale l’accuratezza è massima. Il modello ottimale si ottiene per K = 5.
Relazione fra efficienza dell’algoritmo K-Neighbors al variare del parametro K. Il valore ottimo di accuratezza si ottiene per K=5 (grafico dell’autore)
Diagrammi generati dall’autore in linguaggio Python con le librerie scikit-learn
Risultati K-Neighbors: l’accuratezza di questo modello è del 99,7796%. Ci sono meno falsi positivi e falsi negativi. Solo 16 NEA vengono classificati come non pericolosi mentre in realtà lo sono. Il diagramma di colore mostra le due regioni di classificazione con la linea di separazione: la separazione non può essere lineare ma segue un percorso a zigzag perchè dipende dal concetto di associazione di prossimità calcolato punto per punto.
Albero decisionale: questo classificatore genera un albero così costituito:
ogni nodo rappresenta un attributo
ogni diramazione una regola di decisione basata su una metrica
ogni foglia un risultato (previsione)
L’algoritmo parte dalla radice e partiziona il dataset in funzione del valore di un attributo e procede in maniera iterativa: il processo è simile al procedimento decisionale dell’essere umano. Le principali metriche utilizzate per le definizioni di attributo ed assegnamento dei nodi (le regole di decisione ad ogni livello) si basano sulla definizione e quantità di informazione. Ci possono usare diverse metriche per quantificare l’informazione:
Information Gain (si basa sulla qunatità di entropia)
Gain Ratio (si basa sulla preferenza)
Gini Index (si basa su concetto di probabilità ed è la metrica usata in questa analisi)
Diagrammi generati dall’autore in linguaggio Python con le librerie scikit-learn
Albero decisionale per il modello di ML con i valori dell’indice di Gini e la partizione del dataset in ogni nodo
Diagrammi generati dall’autore in linguaggio Python con le librerie scikit-learn
Risultati Albero decisionale: l’accuratezza di questo modello è del 99,7796%. Il modello identifica correttamente lo stesso numero di NEA pericolosi e non (diagonale principale) ma sbaglia a classificare lo stesso numero complessivo di NEA. C’è una differenza principale rispetto al modello KNeighbors: il numero di NEA identificati erroneamente come non pericolosi quando in realtà essi lo sono (errore peggiore), sono un numero più basso quindi il modello è considerato leggemente migliore. Il diagramma di colore mostra le due regioni di classificazione le linee di separazione associate ad ogni livello di decisione dell’albero.
I modelli KNeighbors e Decision Tree presentano la migliore accuratezza, tuttavia il secondo fornisce i risultati migliori in quanto riesce a minimizzare il numero NEA realmente pericolosi ma erroneamente catalogati come NON pericolosi.
Hazardous Asteroid Classification with Machine Learning using Physical and Orbital, Arjun Ramakrishnan
BBC Scienze – Dicembre 2023, Gennaio 2024
OpenSpace Datasets for Asteroids and Comets
Prendere decisioni avventate esclusivamente sulla base dei risultati ad un modello di A.I. senza ulteriori analisi di un essere umano può portare a decisione errate o conseguenze gravi↩︎
Orologio solare - Ortisei, frazione San Giacomo (BZ)
Orologio solare - Ortisei (BZ)
Orologio solare - Andalo, località Laghett (TN)
Orologio Solare - Brinzio (VA)
Orologio solare, Palazzo del Vescovo - Losanna
Fai della Paganella (TN)
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.





 in grado di classificare i NEA in una delle quattro classi: Aten, Amor, Apollo ed Atira. Per una breve descrizione del funzionamento degli algoritmi presenti si veda anche l’articolo precedente
in grado di classificare i NEA in una delle quattro classi: Aten, Amor, Apollo ed Atira. Per una breve descrizione del funzionamento degli algoritmi presenti si veda anche l’articolo precedente 
![K \in [1 \dots 10]](https://s0.wp.com/latex.php?latex=K+%5Cin+%5B1+%5Cdots+10%5D+&bg=88c3d7&fg=feeca5&s=0&c=20201002) ) e selezionato il valore di K per il quale l’accuratezza è massima. Il modello ottimale si ottiene per K = 9.
) e selezionato il valore di K per il quale l’accuratezza è massima. Il modello ottimale si ottiene per K = 9.












 del dataset X usato come training per l’algoritmo
del dataset X usato come training per l’algoritmo del dataset X usato come test e validazione dell’algoritmo.
del dataset X usato come test e validazione dell’algoritmo. del dataset Y usato come training per l’algoritmo.
del dataset Y usato come training per l’algoritmo. del dataset Y usato come test e validazione dell’algoritmo: costituisce la baseline di riferimento.
del dataset Y usato come test e validazione dell’algoritmo: costituisce la baseline di riferimento.

 con
con  costruendo la matrice di confusione
costruendo la matrice di confusione

 in grado di classificare i NEA in due classi: NEA pericolosi (PHA) o NEA non pericolosi (non PHA). Vengono presentati i risultati di tre modelli:
in grado di classificare i NEA in due classi: NEA pericolosi (PHA) o NEA non pericolosi (non PHA). Vengono presentati i risultati di tre modelli: